Encrypting data with AWS KMS
We recently implemented a new personally identifiable information (PII) storage capability in our app at work. Here’s how we handled encrypting the data at rest.
Key Management
Strong encryption algorithms are well known and widely available in most languages & frameworks, so the larger complexity with encryption these days comes down to managing the master keys used in the algorithms. How do you store the keys securely, restrict access to only authorised applications and use cases, deal with the fallout of accidental leaks, rotate them on a regular cadence to add an extra hurdle for attackers, and a long list of similar challenges?
Historically one of the more secure, though expensive, options for key security was a hardware security module (HSM - you may have seen one make a recent appearance on Mr. Robot!). In the cloud world we have CloudHSM and AWS Key Management Service (KMS). KMS is essentially CloudHSM with some extra resiliency handled by AWS, and offered for a cheaper price via shared HSM tenanting.
The main idea behind KMS (and its underlying HSM functionality) is that the master key never leaves its system boundary. You send the raw data that you want encrypted to KMS, along with an identifier of which key you want to use, then it does its maths magic and returns some encrypted gibberish. This architecture greatly simplifies what you need to think about with regards to potential attack vectors and securing the master keys. KMS is fully PCI DSS compliant and they have a detailed whitepaper describing their various algorithms and internal audit controls to safeguard master keys, if you want to geek out over it :) AWS also offer a best practices guide which we’ve followed quite closely through all this work.
Envelope Encryption
The challenge with KMS is it limits you to encrypting only 4kB of data for performance reasons (you don’t want to send it a 2MB file to encrypt!). That’s fine if you’re encrypting smaller strings like passwords, but for larger amounts of data you have to use a pattern known as envelope encryption. Here’s the encryption flow:
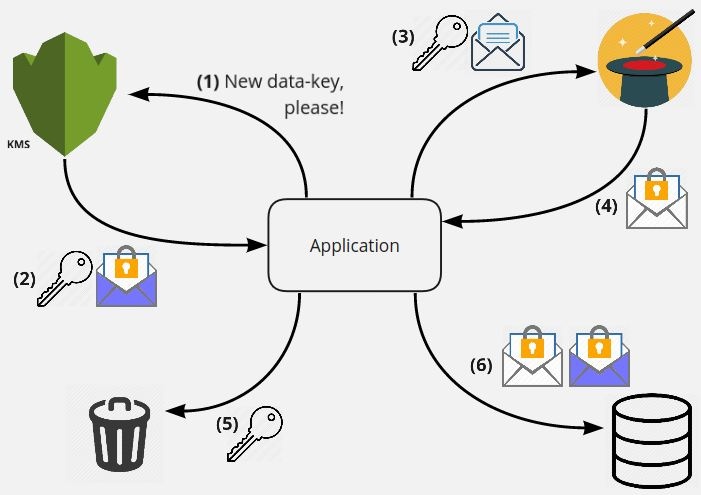
- Ask KMS for a new data-key, specifying which master key you want to use
- Get back both the clear-text data key, and that same key in an encrypted form using your specified master key
- Send the clear-text data key and whatever you want to encrypt to your magical encryption algorithm
- Get back your fully encrypted data from the maths magic
- Bin the clear-text data key, you don’t want it hanging around in-memory or elsewhere!
- Save both the encrypted data-key from KMS and your encrypted data to some data store
Notice that we ask KMS for a new data-key for each encryption operation, so every user gets their own personalised key! That’s a really nice perk we get for free with this setup. So even if we had a data leak, each user is encrypted with a separate key that’d need cracked. The only thing that gives access to all the data is the master key, which is sitting comfortably inside KMS and never leaves. For performance and cost reasons AWS recommend caching those data-keys for a small number of reuses (ie 5 minutes or 10 users), which we’ll look into as we grow the user base and hit scaling issues.
Decryption is basically the reverse of the above:
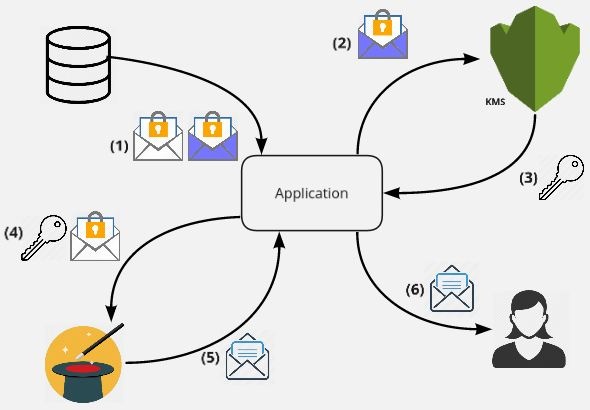
- Retrieve the encrypted data-key and your encrypted data from your data store
- Ask KMS to decrypt the small encrypted data-key using the specified master key
- Get back the clear-text data key
- Use the clear-text data key to decrypt your encrypted data using the same algorithm you used before
- Get back your decrypted data
- Send the decrypted data to your user
This whole process is actually exactly what credstash does under the bonnet!
Master key rotation inside KMS is handled automatically by AWS. The ARN identifier of the master key we use is internally wired to an actual key id that we don’t see. On a yearly basis, AWS can create a new master key and automatically associate it with the public ARN. New encryption calls get the new key, and old users will still get their original master key as KMS keeps all the old ones around indefinitely (all tied to the ARN you use when talking to KMS). We have the option of manually rotating if we want to manage this process ourselves for more frequent rotations or in case of a security breach. This process relies on an alias to point to a new generated key, a full re-encryption of all our data, and removing the old key.
The issue of our control over the master key has also been discussed. If KMS completely broke, AWS went bust, or we, more likely, decided to move encryption providers, we don’t have access to our master keys. We can’t export them, an intentional design decision of KMS. We can generate our own set of keys and use it alongside KMS (or import them into KMS), but this raises many of the same issues KMS is designed to address - how do we secure these keys, guard access to them, etc? For the time being we have decided to accept the risks and rely on KMS completely, knowing that a change would require a full re-encryption of all user’s data.
Encryption Context
Authenticated Encryption with Associated Data (AEAD) is a class of encryption algorithms that help solve the problem of “even though I know my encrypted data is read proof, how do I know it hasn’t been moved about or tampered with”? For example, we can encrypt a user’s profile, but if someone has access to the data store itself and copies the whole encrypted blob from some random record to their record own, then log in with their normal credentials, they’ll see the other user’s data! Most popular encryption algorithms and tools use AEAD to mitigate this, including TLS, IPSec, and SSH (using hostnames). Encryption Context is KMS’ form of associated data that, in part, helps solve this issue. Think of it like a signature for your encrypted blob, helping verify it hasn’t been messed with.
Encryption Context is a plaintext key/value pair that is stored, in the clear, and cryptographically associated with your encrypted blob. These key/value pairs shouldn’t be secret, and for auditability are logged along side all encrypt/decrypt related operations via CloudWatch. For the value you’ll typically use something related to the context that can’t change, such as a record’s primary key or a message’s destination address. We use the user id. This way if some nefarious internal admin moves that encrypted blob to their record, the id’s won’t match and it’s still worthless to them.
Resiliency
We have some super secure encryption with all the above bits, but it does us no good if KMS itself is down, unreachable, or unacceptably slow in a given region. Users wouldn’t be able to create, update, or read any of their personal information! Remember also that the master key, which ultimately encrypts all of our data-keys, can not leave a given KMS’ regional boundary, so two different regions can never have the same master key for us to rely on. How can we support failover without duplicating the encrypted text in each region, and therefore increasing our storage costs? It’s envelope encryption back to save the day!
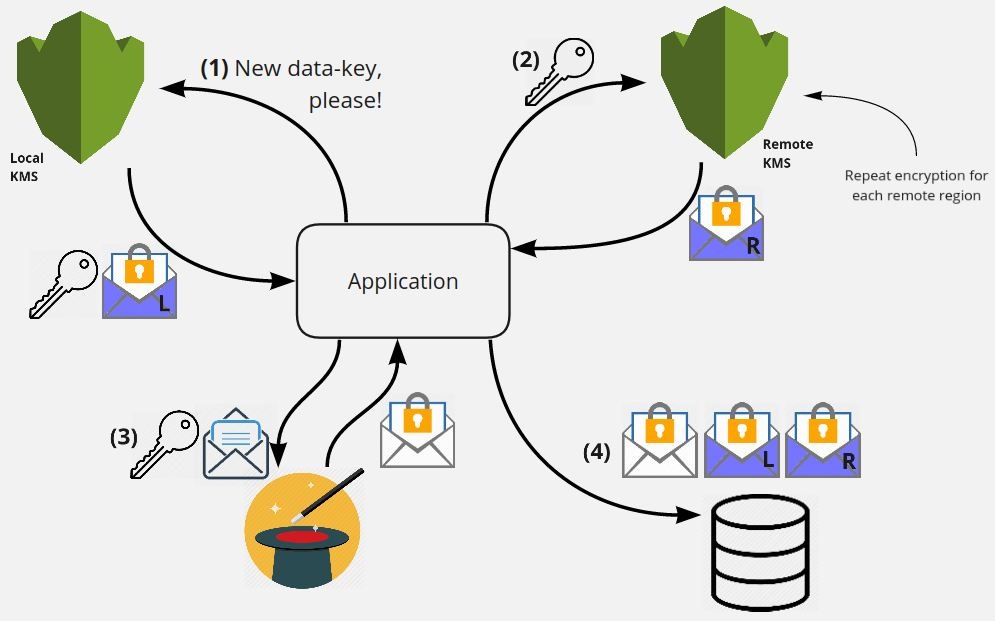
- Ask our local KMS for a data-key, just like we did for encyrption in the previous diagrams
- Send that clear-text data-key to n other remote regions KMS regions, asking each of them to encrypt only the small data-key with their own master key
- Encrypt the data with the clear-text data-key as usual
- Store the encrypted data-key for every region, along with our encrypted data itself, in the data store
Since we’re only storing that extra 4kB worth of encrypted data (the data-key) per region, the overhead of extra regions is minimal. This allows us to try our local KMS region to decrypt, and if it fails for whatever reason, try the next in the list using the encrypted data-key from its region. No matter which KMS region we use, we get back the same clear-text data-key, which we use to decrypt our encrypted data. Nice!
We use a great encryption SDK provided by AWS to do most of the heavy lifting listed in this article. It doesn’t support multi-region encryption just yet though, so we do that ourselves. We also added a simple minimum region setting so we’re not going all over the world encrypting, just a couple of extra regions in the geographic area. Doing this in parallel and other enhancement are possible, but unneeded so far.
Wrap-up
We have learned a lot about KMS while working on our new identity system, including usage patterns, failure scenarios, key permission management, and a host of other topics around encryption. Hopefully it’s never put to the test from a data leak, but we’re confident it’ll protect our user’s personal data if needed!